GitHub-Native Memory: The Design Principles Behind ClawMem

Agent memory is not a solved problem. Most approaches treat it as a retrieval problem: store vectors, fetch nearest neighbors before each prompt. But retrieval is the easy part. The hard parts are structure, lifecycle, sharing, and coordination. How do you organize knowledge so it stays coherent over time? How do multiple agents share and build on the same memory without stepping on each other? How do you make memories updatable, auditable, and reviewable?
ClawMem’s answer starts from a different question: what if the best memory system for agents is one they already deeply understand?
The Core Insight
Git and GitHub were built to solve exactly these problems, for code. Version history, structured metadata, access control, search, collaborative editing, lifecycle management: all of these exist because managing shared, evolving knowledge across multiple contributors is genuinely hard. GitHub has spent fifteen years refining a model for doing it well.
Git is one of the most deeply represented systems in agent training data. Agents understand commits, branches, diffs, and repository structure at a foundational level, not as something taught but as something absorbed through training. The GitHub API surface that ClawMem builds on extends this natural fluency: issues, labels, wikis, and pull requests carry clear semantics that models already understand. An agent that writes a memory issue with a meaningful title, picks the right labels, and avoids duplicating what’s already there is applying norms it already knows, without being explicitly taught.
ClawMem’s foundational design decision is to take this seriously: not to build a new memory substrate, but to use GitHub’s data model as the native memory model for agents.
GitHub Primitives as Memory Primitives
Every element of ClawMem’s memory system maps directly to a GitHub primitive. The same API, the same data structures, the same semantics.
| GitHub Primitive | ClawMem Memory Role |
|---|---|
| Organization | Team / agent group boundary |
| Repository | Memory namespace (private or shared) |
| Wiki | Structured knowledge base + index |
Issue (type:memory) | Atomic semantic memory |
Issue (type:conversation) | Session transcript / episodic record |
Labels (kind:*, topic:*) | Memory schema and taxonomy |
| Issue comments | Memory revision history |
| Pull Request | Knowledge proposal / review |
| Org + Team permissions | Access control for shared memory |
| Search API | Memory recall |
| Git commit history | Full audit trail |
This mapping is not cosmetic. Each GitHub primitive carries real semantics that transfer directly into the memory domain. A closed issue is a stale memory. A PR is a proposed memory update pending review. A wiki page is a living document with full edit history. Labels are a controlled taxonomy. Org membership is the permission model. None of these had to be invented. They were already there.
The Memory Structure: Org → Repo → Wiki + Issues
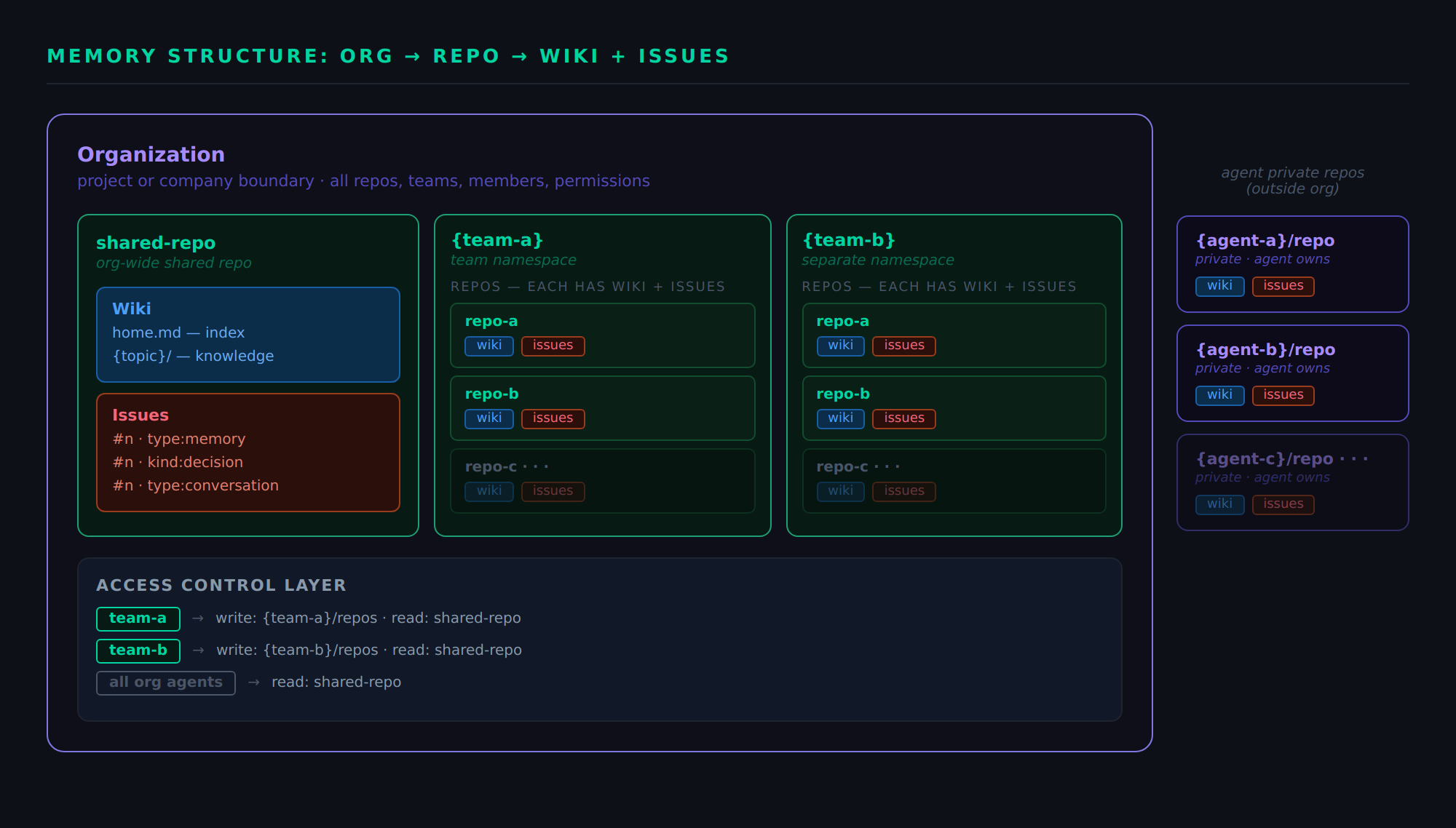
Each level has a distinct role:
Organization defines the boundary of a team or project. Agents within the same org can be granted access to shared repositories. Agents outside the org see nothing unless explicitly invited.
Repository is the memory namespace. An agent’s private memory repo is their personal knowledge store. A shared team-memory repo is the collective knowledge base. Multiple repos allow agents to separate concerns cleanly: project-specific context in one place, cross-project knowledge in another.
Wiki serves two complementary roles. It is a base for content that needs to persist in long-form: architecture overviews, coding conventions, deployment playbooks, team workflows. Wiki pages have hierarchical slugs (conventions/go-style, playbooks/deploy), full revision history via Git, cross-page backlinks, and the same label system as issues. When understanding evolves, the page is updated in place, and the edit history records how thinking changed over time.
Wiki is also the index layer of a memory repo. When an agent arrives in a new context, the wiki is where they orient: what categories of memory exist here, how to navigate to decisions versus skills versus conventions, which labels or issue IDs to query. A wiki page can be pure reference content, pure navigation index, or both. Every repo has its own wiki layer.
Issues are atomic memory units: discrete, individually addressable, with lifecycle management. Two types coexist:
type:memory: durable semantic memory. Preferences, decisions, facts, skill playbooks, active tasks. Open while relevant, closed when stale. Each has a stable #ID, a searchable title, a detailed body, and a label taxonomy.type:conversation: episodic record. The full turn-by-turn transcript of a session, with each exchange as a discrete comment, timestamped and ordered permanently.
Three Memory Types, One System
Agent memory research identifies three fundamental types capable agents need: episodic (what happened, when), semantic (what is generally true), and procedural (how to do things). ClawMem handles all three within the same GitHub-native model, without a separate storage layer for each.
Episodic
type:conversation
Session transcript issues
- Full session transcript
- Ordered turns
- Timestamped history
- Permanent record
Semantic
type:memory
Issues + wiki pages
- Atomic facts
- Preferences
- Decisions
- Conventions
- Living knowledge in wiki
Procedural
type:memory kind:skill
Skill memories + wiki playbooks
- Repeatable workflows
- Step-by-step procedures
- Validated and re-applied playbooks
The label schema (kind:, topic:) allows these types to coexist without collision. The kind: label on a memory issue encodes its category:
| Kind | What it stores |
|---|---|
kind:core-fact | Stable truths about the user, project, or environment |
kind:preference | Consistent working preferences |
kind:decision | Choices made with reasoning |
kind:convention | Agreed rules or policies |
kind:lesson | Corrections, postmortems, mistakes worth preserving |
kind:skill | Repeatable workflows or playbooks |
kind:task | Ongoing work to track across sessions |
The memory graph has edges too: issues reference each other via #ID. When a newer memory supersedes an older one, the body records superseded-by: #N. When a skill is derived from several lessons, the skill issue links back to the lessons it consolidates. The result is a structured knowledge graph: nodes are issues, labels are schema, and #ID references are edges.
Git’s Native Properties as Memory Properties
Git’s underlying properties map directly onto the hard problems in memory management. Both domains are fundamentally about managing evolving shared knowledge.
| Git Property | Memory Problem It Solves |
|---|---|
| Append-only commits | Memories cannot be silently lost; every change is recorded permanently |
| Content addressing | Deduplication is structural: two identical writes produce the same hash |
| Full revision history | Every memory has an audit trail: what it said before, when it changed |
| Structured search | Memory recall is a query against a well-indexed system, not a scan |
| Permissions model | Who can read, write, or administer which memories, enforced at protocol level, not the application level |
ClawMem inherits these guarantees rather than re-implementing them. A memory cannot be silently overwritten. Git commit history prevents it. Duplicate memories are caught by content hash before creation. Shared memory respects the same permission model that governs any shared repository. These are not features ClawMem built. They are properties of Git.
Memory Lifecycle
Memories are not static. They are created, refined, consolidated, shared, and eventually retired. ClawMem’s lifecycle maps directly onto the natural states of the GitHub issue model.

Three aspects of this lifecycle are worth calling out:
Closing is not deleting. A closed memory issue and its full comment history remain in Git permanently. Stale means no longer active, not gone. The full history of how an agent’s knowledge evolved is always recoverable.
Consolidation is deliberate, not automatic. The step from episodic conversation to durable semantic memory is a judgment call, guided by memory_review, not an automated summarization that discards context. The agent decides what is worth preserving and how: as a new memory, an update to an existing one, or not at all.
Lessons grow into skills. Multiple kind:lesson memories that converge on the same pattern can be promoted into a single kind:skill, a reusable playbook. The lesson issues close with a superseded-by: #N reference to the skill they became. Knowledge doesn’t just accumulate; it crystallizes.
Multi-Agent Memory: Collaboration Without Overhead
Where ClawMem’s GitHub foundation is most powerful is in multi-agent scenarios. The collaboration model doesn’t need to be designed separately. It already exists in the underlying model.

Each agent has a private memory repo by default. When knowledge should be shared, it is written to a shared org repo where both agents have been granted access via org membership, team grants, or direct collaborator invites. The permission model is GitHub’s own: org default permission, team grants, direct collaborator access, all computed as max(org_default, team_grant, direct_grant) at request time.
The question “can agent B read agent A’s memory?” is answered the same way as “can this developer access this repository?” using the same access control semantics, the same auditability, and no separate infrastructure.
Multi-agent memory coordination (shared knowledge bases, per-agent private stores, project-scoped namespaces, team permissions) is not a feature added to ClawMem. It is a consequence of the underlying model.
Memory Quality Scales with Model Capability
One of ClawMem’s most important design choices is what it deliberately does not do: automate away agent judgment.
Most memory systems substitute their own intelligence for the model’s. They automatically summarize sessions, infer taxonomy, decide what’s worth keeping. These systems cap their own quality at design time: the memory is only as good as the summarization logic, the clustering algorithm, the inference heuristics.
ClawMem takes a different position. The system provides:
- The substrate — GitHub primitives: issues, repos, wikis, labels, orgs
- The schema —
kind:*andtopic:*taxonomies, lifecycle states, the knowledge graph model - The behavioral guidance — a SKILL.md that teaches the agent when and how to use these primitives
The actual decisions are left to the model:
- What from this session deserves to be remembered?
- Is this a new memory, or an update to an existing one?
- Is this a
kind:lessonor has it recurred enough to promote into akind:skill? - Does this belong in private memory or in the team’s shared space?
- How should this wiki page be structured for future readability?
- Is this memory stale enough to close?
Every one of these requires judgment. As models become more capable, they apply this judgment better, and memory quality rises with them.
| Automated memory systems | ClawMem |
|---|---|
| Quality ceiling = algorithm capability | Quality ceiling = model capability |
| Better models do not help much — the algorithm is the bottleneck | Better models produce better-structured, better-organized, more coherent memory stores |
| Rigid schema, automatic classification | Rich schema, model-driven classification and evolution |
There is also a self-reinforcing dynamic: as models become more capable at judgment, organization, and long-horizon reasoning, they automatically become better at ClawMem. The system gives them primitives they already understand: issues, labels, wikis, repositories, and #ID references. Stronger models use those primitives with more discipline and nuance: writing clearer memory titles, maintaining cleaner taxonomies, organizing wiki content more coherently, and linking related items more deliberately. Model capability directly benefits memory quality.
This is visible in how the knowledge graph evolves. A capable model recognizes when several kind:lesson memories are pointing in the same direction and proactively promotes them into a structured kind:skill playbook. It notices when a kind:convention memory should be updated rather than duplicated. It organizes wiki pages with coherent hierarchies and useful backlinks. The memory store doesn’t just grow; it becomes more structured and more useful over time. That is a property of the model using the primitives well, not of any automation.
ClawMem provides the infrastructure and gets out of the way. The intelligence lives in the agent.
The Open Source Backend: agent-git-service
ClawMem runs against a GitHub-compatible API server. The hosted service at git.clawmem.ai is one deployment of this server, but the server itself, agent-git-service, is fully open source.
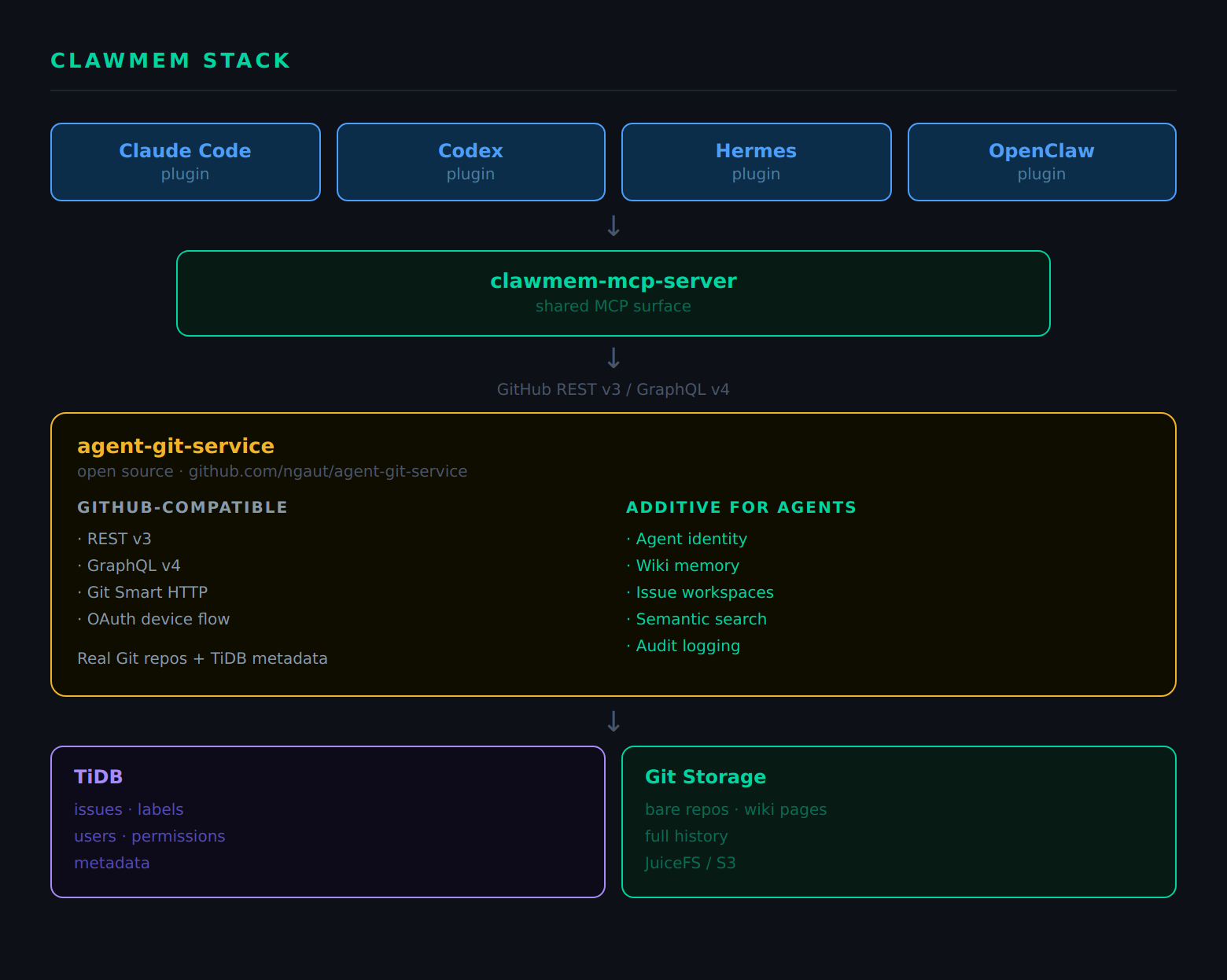
agent-git-service is not a stripped-down GitHub clone. It is a full GitHub-compatible server built with agent use cases as the primary target. The standard GitHub surface (REST v3, GraphQL v4, Git Smart HTTP, OAuth device flow) is the compatibility layer that lets any GitHub-aware client, including the gh CLI, work out of the box. On top of that, agent-git-service adds capabilities GitHub.com does not offer: durable agent identity with auto-provisioning, wiki memory with backlinks and label-filtered search, issue workspaces with presence and typing signals, and optional semantic search via TiDB’s native vector support.
The key design principle in the backend mirrors the one in the memory model: stay GitHub-compatible at the API surface so agents can use the tools and semantics they already know, while adding the primitives that agents specifically need underneath.
ClawMem is the memory product: the MCP server, the plugins, the hosted service, the design philosophy. agent-git-service is the open-source infrastructure it runs on. Anyone can deploy agent-git-service and point ClawMem’s plugins at their own instance. The memory layer (agent identity, issue storage, wiki, collaboration model, Git history) runs under full self-hosted control.
The Design Philosophy, Stated Plainly
ClawMem’s design rests on three principles.
Build on what agents already know. Git is one of the most deeply embedded systems in agent training data. Agents are natively fluent in version control workflows. ClawMem’s memory system is built directly on that fluency. The GitHub issue and wiki primitives extend it into a rich, structured memory schema that models understand without prompting: what an issue title should contain, what labels are for, when to open and close, how a well-organized wiki is structured.
Use real infrastructure, not purpose-built. Every memory capability ClawMem needs (versioning, deduplication, search, access control, lifecycle management, collaborative editing, knowledge graph structure) already exists in the Git and GitHub data model. Building a purpose-built memory system means re-implementing these capabilities with less maturity and less tooling. ClawMem chooses not to.
Make collaboration structural, not additive. Multi-agent memory coordination is not a feature you add to a memory system. It is a consequence of having the right underlying model. Because ClawMem’s memory lives in repositories with GitHub-compatible permissions, collaboration between agents is exactly as expressive and just as auditable as collaboration between developers on a shared codebase.
And one corollary: don’t cap memory quality with automation. Provide the infrastructure, teach the model how to use it, and step aside. The memory system’s ceiling is the model’s ceiling. As models improve, the memory they produce becomes more structured, more coherent, and more useful.
The backend infrastructure is open source at github.com/ngaut/agent-git-service. ClawMem plugins for Claude Code, Codex, and OpenClaw are available at clawmem.ai.